In “Game of Life, hash tables and hash codes” we implemented Conway’s game of Life using Java’s HashMap.
We spent a lot of time (seven articles) optimising hash functions and choosing the best one. The best candidate so far is the function that divides a long value by a big
prime number and returns a remainder; this is the function we’ll be using now. However, the multiplication-based functions also featured quite well, so we mustn’t
forget about them.
Until now we haven’t touched the main algorithm. Now it’s time to do it.
The algorithm
The whole program is in the repository.
The main class is called Life, and the actual Life implementation is called Hash_LongPoint. The code is short, so we can quote it here fully:
public abstract class LongPoint
{
public static abstract class Factory
{
public abstract LongPoint create (long v);
public LongPoint create (int x, int y)
{
return create (fromPoint (x, y));
}
}
final long v;
protected LongPoint (long v)
{
this.v = v;
}
public LongPoint (int x, int y)
{
this.v = fromPoint (x, y);
}
public Point toPoint ()
{
return LongUtil.toPoint (v);
}
@Override
public boolean equals (Object v2)
{
return ((LongPoint) v2).v == v;
}
@Override
public String toString ()
{
return toPoint().toString ();
}
}
final class Hash_LongPoint extends Worker
{
public static final int HASH_SIZE = 8192;
private final LongPoint.Factory factory;
private HashSet<LongPoint> field = new HashSet<LongPoint> (HASH_SIZE);
private HashMap<LongPoint, Integer> counts
= new HashMap<LongPoint, Integer> (HASH_SIZE);
public Hash_LongPoint (LongPoint.Factory factory)
{
this.factory = factory;
}
@Override
public String getName ()
{
return factory.create (0).getClass ().getName ();
}
@Override
public void reset ()
{
field.clear ();
counts.clear ();
}
@Override
public Set<Point> get ()
{
HashSet<Point> result = new HashSet<Point> ();
for (LongPoint p : field) {
result.add (p.toPoint ());
}
return result;
}
private void inc (long w)
{
LongPoint key = factory.create (w);
Integer c = counts.get (key);
counts.put (key, c == null ? 1 : c+1);
}
private void dec (long w)
{
LongPoint key = factory.create (w);
int c = counts.get (key)-1;
if (c != 0) {
counts.put (key, c);
} else {
counts.remove (key);
}
}
void set (LongPoint k)
{
long w = k.v;
inc (w-DX-DY);
inc (w-DX);
inc (w-DX+DY);
inc (w-DY);
inc (w+DY);
inc (w+DX-DY);
inc (w+DX);
inc (w+DX+DY);
field.add (k);
}
void reset (LongPoint k)
{
long w = k.v;
dec (w-DX-DY);
dec (w-DX);
dec (w-DX+DY);
dec (w-DY);
dec (w+DY);
dec (w+DX-DY);
dec (w+DX);
dec (w+DX+DY);
field.remove (k);
}
@Override
public void put (int x, int y)
{
set (factory.create (x, y));
}
@Override
public void step ()
{
ArrayList<LongPoint> toReset = new ArrayList<LongPoint> ();
ArrayList<LongPoint> toSet = new ArrayList<LongPoint> ();
for (LongPoint w : field) {
Integer c = counts.get (w);
if (c == null || c < 2 || c > 3) toReset.add (w);
}
for (LongPoint w : counts.keySet ()) {
if (counts.get (w) == 3 && ! field.contains (w)) toSet.add (w);
}
for (LongPoint w : toSet) {
set (w);
}
for (LongPoint w : toReset) {
reset (w);
}
}
}The classes like LongUtil and Point are not shown here, since they are trivial.
The LongPoint class represents a pair of co-ordinates x and y stored in one long value (32 bits for each). This representation allows moving from a cell to its
neighbours by adding a single offset (see set() and reset()). Various classes derived from LongPoint contain different hashCode() methods. The one we are going to use now
is called LongPoint6, where this method looks like this:
@Override
public int hashCode ()
{
return (int) (v % 946840871);
}The Life implementation maintains two hash-based structures: a hash set field that contains LongPoint objects for all the live cells, and a hash map counts that keeps
number of live neighbours for all the cells where this number is non-zero. Technically it is implemented as a HashMap mapping from LongPoint to Integer. Both structures
are updated when new cells are added or existing cells are removed. Each simulation step (the method step()) analyses field and counts, identifies cells that must be set
and reset (that is, where live cells must be created or destroyed). It uses temporary lists toSet and toReset to delay performing the actions, because it needs the discovery
process to run on unmodified structures.
Since Integer is an immutable class, we can’t increment the values in the counts map when adding a live neighbour. We must allocate a new object with a new value.
We test this code by running 10,000 iterations starting with the configuration called ACORN.
Here are the execution times, in milliseconds:
| Class name | Comment | Time, Java 7 | Time, Java 8 |
|---|---|---|---|
| Hash_LongPoint | Original version | 2032 | 1650 |
Going mutable
The first idea is to replace Integer in counts structure with something mutable. Since there isn’t any readily-made mutable version of Integer, we’ll have to create
our own one called Count. We’ll also move some utility methods into it:
public final class Count
{
public int value;
public Count (int value)
{
this.value = value;
}
public void inc ()
{
++ value;
}
public boolean dec ()
{
return --value != 0;
}
}The new Life implementation is called Hash1 (see here).
The first thing we need is a new definition for counts:
private HashMap<LongPoint, Count> counts
= new HashMap<LongPoint, Count> (HASH_SIZE);Then we must modify inc() and dec():
private void inc (long w)
{
LongPoint key = factory.create (w);
Count c = counts.get (key);
if (c == null) {
counts.put (key, new Count (1));
} else {
c.inc ();
}
}
private void dec (long w)
{
LongPoint key = factory.create (w);
if (! counts.get (key).dec ()) {
counts.remove (key);
}
}Unlike Integer, the new class Count does not support automatic boxing and unboxing, that’s why step() must be changed as well:
public void step ()
{
ArrayList<LongPoint> toReset = new ArrayList<LongPoint> ();
ArrayList<LongPoint> toSet = new ArrayList<LongPoint> ();
for (LongPoint w : field) {
Count c = counts.get (w);
if (c == null || c.value < 2 || c.value > 3) toReset.add (w);
}
for (LongPoint w : counts.keySet ()) {
if (counts.get (w).value == 3 && ! field.contains (w)) {
toSet.add (w);
}
}
for (LongPoint w : toSet) {
set (w);
}
for (LongPoint w : toReset) {
reset (w);
}
}This is the new execution time:
| Class name | Comment | Time, Java 7 | Time, Java 8 |
|---|---|---|---|
| Hash_LongPoint | Original version | 2032 | 1650 |
| Hash1 | Mutable Count | 1546 | 1437 |
This is not bad, especially on Java 7.
Merging the hash maps
Why do we have two hash maps (a hash set is internally a hash map) in the first place? The primary motivation for this decision was the clarity of code. Besides,
keeping counts separately from the information on live cells allowed using standard Java class Integer as the value type of a hash map. As we have introduced
our own class, nothing prevents us from adding to it whatever other fields we consider useful. It would have been beneficial to keep two hash maps separately if
we only ever iterated the smaller one of them (field). We, however, iterate both, which is another argument in favour of merging them and iterating both at once.
Let’s introduce a new class, called Value,
which will contain both neighbour information and the status of the cell:
public final class Value
{
public int count;
public boolean live;
public Value (int value, boolean present)
{
this.count = value;
this.live = present;
}
public Value (int value)
{
this (value, false);
}
public void inc ()
{
++ count;
}
public boolean dec ()
{
return --count != 0;
}
public void set ()
{
live = true;
}
public void reset ()
{
live = false;
}
}Note that both live cells with zero live neighbours, and dead cells with live neighbours occur in real life, so there is no redundancy in the fields. Care should be taken
to remove cells only when count == 0 && !live. Let’s make a new implementation, Hash2.
First, we replace two hash structures with one:
private HashMap<LongPoint, Value> field
= new HashMap<LongPoint, Value> (HASH_SIZE);The methods inc() and dec() must now work with the new class:
private void inc (long w)
{
LongPoint key = factory.create (w);
Value c = field.get (key);
if (c == null) {
field.put (key, new Value (1));
} else {
c.inc ();
}
}
private void dec (long w)
{
LongPoint key = factory.create (w);
Value v = field.get (key);
if (! v.dec () && ! v.live) {
field.remove (key);
}
}set() and reset() must also change: modifying of the live status of a cell now requires a couple of extra lines:
void set (LongPoint k)
{
long w = k.v;
inc (w-DX-DY);
inc (w-DX);
inc (w-DX+DY);
inc (w-DY);
inc (w+DY);
inc (w+DX-DY);
inc (w+DX);
inc (w+DX+DY);
Value c = field.get (k);
if (c == null) {
field.put (k, new Value (0, true));
} else {
c.live = true;
}
}
void reset (LongPoint k)
{
long w = k.v;
dec (w-DX-DY);
dec (w-DX);
dec (w-DX+DY);
dec (w-DY);
dec (w+DY);
dec (w+DX-DY);
dec (w+DX);
dec (w+DX+DY);
Value v = field.get (k);
if (v.count == 0) {
field.remove (k);
} else {
v.live = false;
}
}Finally, the main iteration function must only iterate one structure:
public void step ()
{
ArrayList<LongPoint> toReset = new ArrayList<LongPoint> ();
ArrayList<LongPoint> toSet = new ArrayList<LongPoint> ();
for (LongPoint w : field.keySet ()) {
Value c = field.get (w);
if (c.live) {
if (c.count < 2 || c.count > 3) toReset.add (w);
} else {
if (c.count == 3) toSet.add (w);
}
}
for (LongPoint w : toSet) {
set (w);
}
for (LongPoint w : toReset) {
reset (w);
}
}Here are the results:
| Class name | Comment | Time, Java 7 | Time, Java 8 |
|---|---|---|---|
| Hash1 | Mutable Count | 1546 | 1437 |
| Hash2 | A unified hash map | 1309 | 1163 |
This change has also resulted in a good speed improvement.
A minor improvement: unnecessary check
The set() method contains a null check:
void set (LongPoint k)
{
long w = k.v;
inc (w-DX-DY);
inc (w-DX);
inc (w-DX+DY);
inc (w-DY);
inc (w+DY);
inc (w+DX-DY);
inc (w+DX);
inc (w+DX+DY);
Value c = field.get (k);
if (c == null) {
field.put (k, new Value (0, true));
} else {
c.live = true;
}
}This check is unnecessary during iterations: set() is always called on a cell that is present in the field structure (its neighbour count is 3).
We can remove this check (see Hash3):
void set (LongPoint k)
{
long w = k.v;
inc (w-DX-DY);
inc (w-DX);
inc (w-DX+DY);
inc (w-DY);
inc (w+DY);
inc (w+DX-DY);
inc (w+DX);
inc (w+DX+DY);
Value c = field.get (k);
c.live = true;
}This check, however, is needed during initial population of the field. We’ll have to modify the initial population routine accordingly, from
public void put (int x, int y)
{
set (factory.create (x, y));
}to
public void put (int x, int y)
{
LongPoint k = factory.create (x, y);
if (! field.containsKey (k)) {
field.put (k, new Value (0));
}
set (k);
}| Class name | Comment | Time, Java 7 | Time, Java 8 |
|---|---|---|---|
| Hash2 | A unified hash map | 1309 | 1163 |
| Hash3 | Check in set removed | 1312 | 1151 |
This hasn’t achieved much, but it was, after all, a minor change (unlike the two previous ones).
Another minor improvement: entry iterator
This fragment in step()
for (LongPoint w : field.keySet ()) {
Value c = field.get (w);is inefficient: we are looking up in the hash map the key value that has just been extracted from the same hash map during iteration. This can be easily eliminated
(see Hash4):
public void step ()
{
ArrayList<LongPoint> toReset = new ArrayList<LongPoint> ();
ArrayList<LongPoint> toSet = new ArrayList<LongPoint> ();
for (Entry<LongPoint, Value> w : field.entrySet ()) {
Value c = w.getValue ();
if (c.live) {
if (c.count < 2 || c.count > 3) toReset.add (w.getKey ());
} else {
if (c.count == 3) toSet.add (w.getKey ());
}
}
for (LongPoint w : toSet) {
set (w);
}
for (LongPoint w : toReset) {
reset (w);
}
}| Class name | Comment | Time, Java 7 | Time, Java 8 |
|---|---|---|---|
| Hash3 | Check in set removed | 1312 | 1151 |
| Hash4 | Entry iterator in the loop | 1044 | 976 |
Another big improvement.
More use of HashMap.Entry objects
Both set() and reset() use their LongPoint parameter to look up corresponding cell in the field structure. This is unnecessary, since the cell is already known:
after all, the reason for call to set() or reset() is that the program has established some fact about the cell (variable c in step()). The reference to this cell
is lost, because we populate toSet and toReset with the key values. It would be nice to put both keys and values there, and pass both as parameters to set() and reset().
This is easy to achieve: all we need is declare toReset and toSet as ArrayList<Entry<LongPoint, Value>>
(see Hash5):
void set (LongPoint k, Value v)
{
long w = k.v;
inc (w-DX-DY);
inc (w-DX);
inc (w-DX+DY);
inc (w-DY);
inc (w+DY);
inc (w+DX-DY);
inc (w+DX);
inc (w+DX+DY);
v.live = true;
}
void reset (LongPoint k, Value v)
{
long w = k.v;
dec (w-DX-DY);
dec (w-DX);
dec (w-DX+DY);
dec (w-DY);
dec (w+DY);
dec (w+DX-DY);
dec (w+DX);
dec (w+DX+DY);
if (v.count == 0) {
field.remove (k);
} else {
v.live = false;
}
}
public void step ()
{
ArrayList<Entry<LongPoint, Value>> toReset
= new ArrayList<Entry<LongPoint, Value>> ();
ArrayList<Entry<LongPoint, Value>> toSet
= new ArrayList<Entry<LongPoint, Value>> ();
for (Entry<LongPoint, Value> w : field.entrySet ()) {
Value c = w.getValue ();
if (c.live) {
if (c.count < 2 || c.count > 3) toReset.add (w);
} else {
if (c.count == 3) toSet.add (w);
}
}
for (Entry<LongPoint, Value> w : toSet) {
set (w.getKey (), w.getValue ());
}
for (Entry<LongPoint, Value> w : toReset) {
reset (w.getKey (), w.getValue ());
}
}The initial population routine must be changed as well:
@Override
public void put (int x, int y)
{
LongPoint k = factory.create (x, y);
Value v = field.get (k);
if (v == null) {
field.put (k, v = new Value (0));
}
set (k, v);
}| Class name | Comment | Time, Java 7 | Time, Java 8 |
|---|---|---|---|
| Hash4 | Entry iterator in the loop | 1044 | 976 |
| Hash5 | ArrayList<Entry> introduced | 1006 | 975 |
Strangely, the improvement isn’t great; I expected much better results.
Re-using the ArrayList
Two new ArrayList objects are allocated each time step is executed. This on its own isn’t too bad: object allocation is fast in Java, and step() is only
executed 10,000 times. However, there is additional cost: management of the array that backs the ArrayList. This array is allocated small (size 10), then it is expanded as
the ArrayList grows. The rule for expanding is
int newCapacity = oldCapacity + (oldCapacity >> 1);This means that the array will be allocated of size 10, 15, 22, 33, 49, 73, 109, 163, 244 and so on – nine allocations for a list size of 250, which is typical for our
program. While staying with ArrayList class, we can’t avoid checking for sufficient capacity, but can avoid re-allocation. All we need is re-use the arrays:
we put the following in the beginning of the new class (Hash6):
private final ArrayList<Entry<LongPoint, Value>> toReset
= new ArrayList<Entry<LongPoint, Value>> ();
private final ArrayList<Entry<LongPoint, Value>> toSet
= new ArrayList<Entry<LongPoint, Value>> ();Instead of allocating an array, it is sufficient to clear it:
public void step ()
{
toReset.clear ();
toSet.clear ();
for (Entry<LongPoint, Value> w : field.entrySet ()) {
...| Class name | Comment | Time, Java 7 | Time, Java 8 |
|---|---|---|---|
| Hash5 | ArrayList<Entry> introduced | 1006 | 975 |
| Hash6 | Re-used ArrayList<Entry> | 1097 | 947 |
Strangely, the improvement only happened on Java 8, and even there it isn’t big. Does it mean that object allocation isn’t such a big expense?
ArrayList vs an array
What if we replace ArrayList objects with simply arrays? If we allocate these arrays of right size, we can save on resize checks when we fill the array. We will also save
on the iterator when we iterate it. This is not the recommended way to program in Java, since it causes us to write code that duplicates the code of the Java
standard library. We will still do it to check if it provides any speed advantage.
Let’s define two arrays of appropriate types and of some reasonable size (see Hash7):
private Entry<LongPoint, Value> [] toReset = new Entry [128];
private Entry<LongPoint, Value> [] toSet = new Entry [128];javac gives warning on these lines:
Hash7.java:17: warning: [unchecked] unchecked conversion
private Entry<LongPoint, Value> [] toReset = new Entry [128];
^
required: Entry<LongPoint,Value>[]
found: Entry[]
I don’t know of any way to get rid of this warning (except @SupressWarnings), so we’ll have to live with it.
In the beginning of step() we must make sure both arrays are of sufficient size. We are not short of memory. Why not allocate it of size field.size(), or, to prevent
frequent resizing, even bigger?
public void step ()
{
if (field.size () > toSet.length) {
toReset = new Entry [field.size () * 2];
toSet = new Entry [field.size () * 2];
}
int setCount = 0;
int resetCount = 0;
for (Entry<LongPoint, Value> w : field.entrySet ()) {
Value c = w.getValue ();
if (c.live) {
if (c.count < 2 || c.count > 3) toReset[resetCount ++] = w;
} else {
if (c.count == 3) toSet[setCount ++] = w;
}
}
for (int i = 0; i < setCount; i++) {
set (toSet[i].getKey (), toSet[i].getValue ());
toSet[i] = null;
}
for (int i = 0; i < resetCount; i++) {
reset (toReset[i].getKey (), toReset[i].getValue ());
toReset[i] = null;
}
}Note that we set used elements of the arrays to null. This is done to improve garbage collection. If we don’t clean the arrays, some elements at the high indices may
stay alive and contaminate memory forever. We can, however, clean the arrays now and then rather than each time, but I don’t think this cleanup introduces a significant overhead.
Here are the results:
| Class name | Comment | Time, Java 7 | Time, Java 8 |
|---|---|---|---|
| Hash6 | Re-used ArrayList<Entry> | 1097 | 947 |
| Hash7 | ArrayList replaced with an array | 1020 | 904 |
There is some improvement, although not as big as we expected.
The overall results
Here are the results for all the versions we tried today:
| Class name | Comment | Time, Java 7 | Time, Java 8 |
|---|---|---|---|
| Hash_LongPoint | Original version | 2032 | 1650 |
| Hash1 | Mutable Count | 1546 | 1437 |
| Hash2 | A unified hash map | 1309 | 1163 |
| Hash3 | Check in set removed | 1312 | 1151 |
| Hash4 | Entry iterator in the loop | 1044 | 976 |
| Hash5 | ArrayList<Entry> introduced | 1006 | 975 |
| Hash6 | Re-used ArrayList<Entry> | 1097 | 947 |
| Hash7 | ArrayList replaced with an array | 1020 | 904 |
The best results were achieved by:
-
introducing mutable counts (24% on Java 7; 13% on Java 8)
-
unifying two hash maps (15% on Java 7; 19% on Java 8)
-
iterating over the set of
Entryobjects (20% on Java 7; 15% on Java 8)
It is interesting that the main idea of one of these changes (the mutable counts) is
“replace standard Java classes with something custom made for the job”, one (unifying the maps) is very close to it (“use less of the standard classes”),
and only the Entry iterator change is based on much more moderate idea “Use Java standard classes optimally”.
Here are the results in the graphic form:
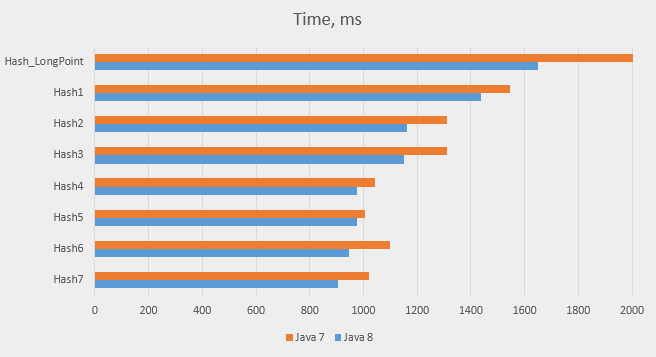
The overall improvement is quite good, it was 50% for Java 7 and 45% for Java 8, which means that we’ve made the program almost twice as fast.
Some statistics
Our improved implementation uses much less hash map operations than the initial ones. Here are the stats:
| Operation | Old counts | New counts | |
|---|---|---|---|
field | counts | field | |
put(), new | 1,292,359 | 2,481,224 | 2,470,436 |
put(), update | 0 | 15,713,009 | 0 |
get(), success | 1,708,139 | 48,514,853 | 18,202,363 |
get(), fail | 1,292,359 | 2,497,339 | 2,470,436 |
remove() | 1,291,733 | 2,478,503 | 2,467,681 |
| All operations | 5,584,590 | 71,684,928 | 25,610,916 |
hashCode() | 77,269,518 | 25,610,916 | |
The total number of times hashCode() is called dropped by two thirds.
Other hash functions
Since the total number of performed hash map operations has dropped, the fraction of time spent in these operations may have changed, and this may have caused
different relative performance of the hash functions. Let’s run the Hash7 version with some of the previously tested hash functions (excluding very slow ones).
Here are the old and the new results:
| Class name | Comment | Hash_LongPoint | Hash7 | Java 7 | Java 8 | Java 7 | Java 8 | </tr>
|---|---|---|---|---|---|
| LongPoint1 | Multiply by 3, 5 | 2719 | 4809 | 1344 | 2361 |
| LongPoint3 | Multiply by 11, 17 | 2257 | 1928 | 1139 | 1109 |
| LongPoint4 | Multiply by two big primes | 2128 | 1611 | 1160 | 932 |
| LongPoint5 | Multiply by one big prime | 2150 | 1744 | 1189 | 914 |
| LongPoint6 | Modulo big prime | 2032 | 1650 | 1020 | 904 |
| LongPoint75 | CRC32, written in Java | 3522 | 2664 | 1641 | 1308 |
| LongPoint77 | CRC32C, written in C using SSE, one JNI call | 2409 | 2045 | 1254 | 1072 |
The relative performance stayed the same. The functions that caused poor performance are still causing poor performance. The division-based function (LongPoint6) is still
the best, two multiplication-based ones (LongPoint4 and LongPoint5) being very close.
Conclusions
-
Our initial implementation could be improved a lot; by 50% on Java 7 and by 45% on Java 8.
-
The biggest improvement was caused by replacing of standard classes with the hand-made ones and by using the standard classes more efficiently.
-
The choice of the hash function is still important.
Coming soon
This seems to be the limit: it looks as if there is nothing to improve in our program. However, there are some more ideas. We’ll start by looking at the hash table size; that will be the topic of the next article.