Today we’ll look at one of the most basic and the most often used methods from the Java library: System.currentTimeMillis().
This method reports current time with the millisecond accuracy. One may think that, because of this, the performance of this method is irrelevant. Who cares if obtaining current time takes 0.1 or 0.2 ms if the measured interval is 100 or 500 milliseconds long? There are, however, cases when we might still want to invoke this method frequently. Here are the examples:
-
Detecting and reporting abnormally long execution times. For instance, we can measure the time it takes to execute an HTTP request. In most cases (we hope) it takes below one milliseconds, which will report as zero if we use this method, but we want to be alarmed if the measured time is abnormally long (e.g. exceeds 100 ms). In this case we’ll time every request, and there may be hundreds of thousands, or even millions, of them per second.
-
Obtaining timestamps to be associated with some objects, for instance, with cached data – to arrange time-based eviction from a cache.
-
Measuring the duration of some long, but frequently initiated asynchronous processes, such as requests to remote servers.
-
Time-stamping some real-world events. For instance, a trading system may wish to record timestamps of incoming orders and performed deals.
In short, despite rather low accuracy of this method, there are cases when it can be called very often, so a very valid question arises: what is the performance of this method?
Measuring speed
The way to test the performance of currentTimeMillis() is straightforward: we call it many times, while making sure that it isn’t optimised out altogether:
static void test_milli_speed ()
{
long sum = 0;
int N = 100000000;
long t1 = System.currentTimeMillis ();
for (int i = 0; i < N; i++)
sum += System.currentTimeMillis ();
long t2 = System.currentTimeMillis ();
System.out.println ("Sum = " + sum + "; time = " + (t2 - t1) +
"; or " + (t2 - t1) * 1.0E6 / N + " ns / iter");
}Running it on Windows (my notebook, which is Windows 10, Core i7-6820HQ @2.7GHz), using Java 1.8.0_92, we get:
>java Time
Sum = 2276735854871496107; time = 393; or 3.93 ns / iter
Sum = 2276735892808191170; time = 382; or 3.82 ns / iter
Sum = 2276735930338889327; time = 379; or 3.79 ns / iter
This is very good result. When time is reported in 3.8 ns, we can put time request instructions just about anywhere. We can measure time of any operation and attach timestamp to any resource. It is virtually free. We can query time 260 million times per second.
Let’s run it on Linux. The one I use for testing is of RHEL flavour with a kernel version of 3.17.4, and it runs on a dual Xeon® CPU E5-2620 v3 @ 2.40GHz.
# java Time
Sum = 1499457980079543330; time = 652; or 652.0 ns / iter
Sum = 1499457980725968363; time = 642; or 642.0 ns / iter
Sum = 1499457981368550493; time = 643; or 643.0 ns / iter
We had to reduce the iteration count by a couple of zeroes (make it one million), because the test runs two hundred times longer. The average time to query time in Linux is 640 ns, which is more than half a microsecond. We can only execute this call 1.5 million times per second.
This is really shocking, and it means for us that we must be careful with our use of currentTimeMillis() on Linux. While still applicable for measuring
time of sequential long operations, this method can’t really be used for the tasks listed above.
Why is this and what can be done?
Windows version
The currentTimeMillis() is a native function. Its code can be found in OpenJDK distribution, where it is linked to JVM_CurrentTimeMillis
(file hotspot/src/share/vm/prims/jvm.cpp), which eventually ends up at os::javaTimeMillis(). This call is OS-dependent.
The Windows version of this code (hotspot/src/os/windows/vm/jvm.cpp/os_windows.cpp) looks like this:
jlong os::javaTimeMillis() {
if (UseFakeTimers) {
return fake_time++;
} else {
FILETIME wt;
GetSystemTimeAsFileTime(&wt);
return windows_to_java_time(wt);
}
}
jlong windows_to_java_time(FILETIME wt) {
jlong a = jlong_from(wt.dwHighDateTime, wt.dwLowDateTime);
return (a - offset()) / 10000;
}
static jlong _offset = 116444736000000000;
jlong offset() {
return _offset;
}Java time is based on GetSystemTimeAsFileTime(), which returns a FILETIME. This structure dates back to 32-bit systems, and consists of two 32-bit fields,
dwHighDateTime and dwLowDateTime, which, combined together, define a 64-bit number of 100-nanosecond intervals since the epoch time.
In MSVC, we can call this function and trace its execution in a debugger. The disassembly in the 32-bit mode shows its code:
7691C450 mov edi,edi
7691C452 push ebp
7691C453 mov ebp,esp
7691C455 push ebx
7691C456 push esi
7691C457 push edi
7691C458 mov esi,7FFE0018h
7691C45D mov edi,7FFE0014h
7691C462 mov ebx,7FFE001Ch
7691C467 mov eax,dword ptr [esi]
7691C469 mov edx,dword ptr [edi]
7691C46B mov ecx,dword ptr [ebx]
7691C46D cmp eax,ecx
7691C46F jne 7691C480
7691C471 mov ecx,dword ptr [ebp+8]
7691C474 pop edi
7691C475 pop esi
7691C476 pop ebx
7691C477 mov dword ptr [ecx],edx
7691C479 mov dword ptr [ecx+4],eax
7691C47C pop ebp
7691C47D ret 4
7691C480 pause
7691C482 jmp 7691C467This is indeed very clever. The function contains no system calls. Everything happens in the user space. There is a memory area that is mapped into the address space of every process. Some background thread regularly updates three double-words there, which contain the high part of the value, the low part, and the high part again. The client reads all three, in this order, and, if the two high parts are equal, the low part is considered consistent with them (the strong memory access ordering of x86 guarantees this). If not, the procedure must be repeated. This is very unlikely event, that’s why the entire procedure is so fast.
The function looks even better in the 64-bit mode:
00007FF90970CE80 mov eax,7FFE0014h
00007FF90970CE85 mov rax,qword ptr [rax]
00007FF90970CE88 mov dword ptr [rcx],eax
00007FF90970CE8A shr rax,20h
00007FF90970CE8E mov dword ptr [rcx+4],eax
00007FF90970CE91 retHere the background thread can write the value atomically, and the client can atomically read it. Actually, the code could have been even better – we could write a 64-bit value in one instruction:
mov eax,7FFE0014h
mov rax,qword ptr [rax]
mov qword ptr [rcx],rax
retHowever, the code is much faster than any possible system call anyway.
What is the resolution of this timer? Let’s collect the values into an array and print it later:
#define N 1000000
int values[N];
int main(void)
{
int i;
for (i = 0; i < N; i++) {
FILETIME f;
GetSystemTimeAsFileTime (&f);
values[i] = (int) f.dwLowDateTime;
}
for (i = 1; i < N; i++)
if (values[i-1] != values[i])
printf("%d %d\n", i, values[i] - values[i-1]);
return 0;
}The output is:
68208 5044
214315 5015
362575 5037
508633 4987
654960 5022
800065 5007
943784 5041
The timer ticks roughly once every half a millisecond (2000 Hz). This is perfectly adequate to serve as a base of currentTimeMillis().
Linux version
This happened to be much longer journey than I expected. We start at another version of os::javaTimeMillis(), in
hotspot/src/os/linux/vm/os_linux.cpp:
jlong os::javaTimeMillis() {
timeval time;
int status = gettimeofday(&time, NULL);
assert(status != -1, "linux error");
return jlong(time.tv_sec) * 1000 + jlong(time.tv_usec / 1000);
}It is very unlikely that the time is spent in multiplication or division by 1000, but let’s measure the performance of gettimeofday anyway:
volatile uint64_t tt;
int main (void)
{
int i;
int N = 10000000;
struct timeval time;
uint64_t t0 = 0;
for (i = 0; i < N; i++) {
gettimeofday (&time, 0);
tt = time.tv_sec * (uint64_t) 1000000 + time.tv_usec;
if (t0 == 0) t0 = tt;
}
printf ("Time for %d: %f s; %f ns\n",
N, (tt - t0) * 1.0E-6, (tt - t0) * 1.0E3 / N);
return 0;
}Running it, we get:
Time for 10000000: 6.251108 s; 625.110800 ns
The call to gettimeofday is indeed slow. Why? Is there perhaps some system call involved?
Let’s run it in the gdb. After we have stepped into the call of gettimeofday, we see this:
Dump of assembler code for function gettimeofday@plt:
=> 0x0000000000400460 <+0>: jmpq *0x200bba(%rip) # 0x601020 <gettimeofday@got.plt>
0x0000000000400466 <+6>: pushq $0x1
0x000000000040046b <+11>: jmpq 0x400440The first jmpq in fact jumps to the next instruction (+6), and eventually we end up in a function called _dl_runtime_resolve.
What is actually happening here is that we are linking to the vDSO (virtual dynamic shared object), which is a small fully relocatable shared library
pre-mapped into the user address space. The linking happens during the first call of gettimeofday, after which the call is resolved, and the first indirect jump
goes straight into the function. Let’s skip this execution and break before the next call to gettimeofday. The function looks the same:
=> 0x0000000000400460 <+0>: jmpq *0x200bba(%rip) # 0x601020 <gettimeofday@got.plt>but this time the jump takes us to the real implementation. Here it is, with some added comments:
Dump of assembler code for function gettimeofday:
=> 0x00007ffff7ffae50 <+0>: push %rbp
0x00007ffff7ffae51 <+1>: mov %rsp,%rbp
0x00007ffff7ffae54 <+4>: push %r15
0x00007ffff7ffae56 <+6>: push %r14
0x00007ffff7ffae58 <+8>: push %r13
0x00007ffff7ffae5a <+10>: push %r12
0x00007ffff7ffae5c <+12>: push %rbx
0x00007ffff7ffae5d <+13>: sub $0x18,%rsp
0x00007ffff7ffae61 <+17>: test %rdi,%rdi
0x00007ffff7ffae64 <+20>: je 0x7ffff7ffaf45 <gettimeofday+245> ; if (tv == NULL)
; gtod_read_begin
0x00007ffff7ffae6a <+26>: mov -0x2df1(%rip),%r8d # 0x7ffff7ff8080 ; gtod->seq
0x00007ffff7ffae71 <+33>: mov $0x7b,%eax
0x00007ffff7ffae76 <+38>: mov $0xffffffffff7ff000,%r12
0x00007ffff7ffae7d <+45>: lsl %ax,%ebx
0x00007ffff7ffae80 <+48>: xor %r15d,%r15d
0x00007ffff7ffae83 <+51>: mov %ebx,%r11d
0x00007ffff7ffae86 <+54>: test $0x1,%r8b ; if (gtod->seq &1)
0x00007ffff7ffae8a <+58>: jne 0x7ffff7ffb0ed <gettimeofday+669> ; gtod->seq & 1 : cpu_relax and repeat
0x00007ffff7ffae90 <+64>: mov -0x2def(%rip),%rax # 0x7ffff7ff80a8 ; gtod->wall_time_sec
0x00007ffff7ffae97 <+71>: mov -0x2e1a(%rip),%r9d # 0x7ffff7ff8084 ; gtod->vclock_mode
0x00007ffff7ffae9e <+78>: mov %rax,(%rdi) ; ts->tv_sec
0x00007ffff7ffaea1 <+81>: mov -0x2e23(%rip),%edx # 0x7ffff7ff8084 ; gtod->vclock_mode
0x00007ffff7ffaea7 <+87>: mov -0x2e0e(%rip),%r14 # 0x7ffff7ff80a0 ; gtod->wall_time_snsec
0x00007ffff7ffaeae <+94>: cmp $0x1,%edx ; 1 = VCLOCK_TSC
0x00007ffff7ffaeb1 <+97>: je 0x7ffff7ffb090 <gettimeofday+576>
0x00007ffff7ffaeb7 <+103>: cmp $0x2,%edx ; 2 = VCLOCK_HPET
0x00007ffff7ffaeba <+106>: je 0x7ffff7ffb070 <gettimeofday+544>
0x00007ffff7ffaec0 <+112>: xor %eax,%eax
0x00007ffff7ffaec2 <+114>: cmp $0x3,%edx ; 3 = VCLOCK_PVCLOCK
0x00007ffff7ffaec5 <+117>: mov -0x2ebc(%rip),%r13d # 0x7ffff7ff8010
0x00007ffff7ffaecc <+124>: je 0x7ffff7ffaf63 <gettimeofday+275>
0x00007ffff7ffaed2 <+130>: mov -0x2e3c(%rip),%ecx # 0x7ffff7ff809c ; gtod->shift
0x00007ffff7ffaed8 <+136>: mov -0x2e5e(%rip),%edx # 0x7ffff7ff8080 ; gtod->seq
0x00007ffff7ffaede <+142>: cmp %r8d,%edx ; start
0x00007ffff7ffaee1 <+145>: jne 0x7ffff7ffb0cd <gettimeofday+637> ; jne if retry
0x00007ffff7ffaee7 <+151>: lea (%r14,%rax,1),%r8
0x00007ffff7ffaeeb <+155>: shr %cl,%r8
0x00007ffff7ffaeee <+158>: mov (%rdi),%rcx
;__iter_div_u64_rem(ns, NSEC_PER_SEC, &ns);
0x00007ffff7ffaef1 <+161>: cmp $0x3b9ac9ff,%r8 ; 999 999 999
0x00007ffff7ffaef8 <+168>: jbe 0x7ffff7ffb0b5 <gettimeofday+613>
0x00007ffff7ffaefe <+174>: xor %edx,%edx
0x00007ffff7ffaf00 <+176>: sub $0x3b9aca00,%r8 ; 1 000 000 000
0x00007ffff7ffaf07 <+183>: add $0x1,%edx
0x00007ffff7ffaf0a <+186>: cmp $0x3b9ac9ff,%r8 ; 999 999 999
0x00007ffff7ffaf11 <+193>: ja 0x7ffff7ffaf00 <gettimeofday+176>
0x00007ffff7ffaf13 <+195>: add %rcx,%rdx
0x00007ffff7ffaf16 <+198>: test %r9d,%r9d
0x00007ffff7ffaf19 <+201>: mov %r8,0x8(%rdi) ; ts->tv_nsec = ns
0x00007ffff7ffaf1d <+205>: mov %rdx,(%rdi) ; ts->tv_sec = sec
0x00007ffff7ffaf20 <+208>: je 0x7ffff7ffb0fb <gettimeofday+683> ; vdso_fallback_gtod if mode == VCLOCK_NONE ? (never true)
0x00007ffff7ffaf26 <+214>: mov %r8,%rax ; tv->tv_usec /= 1000;
0x00007ffff7ffaf29 <+217>: movabs $0x20c49ba5e353f7cf,%rdx
0x00007ffff7ffaf33 <+227>: sar $0x3f,%r8
0x00007ffff7ffaf37 <+231>: imul %rdx
0x00007ffff7ffaf3a <+234>: sar $0x7,%rdx
0x00007ffff7ffaf3e <+238>: sub %r8,%rdx
0x00007ffff7ffaf41 <+241>: mov %rdx,0x8(%rdi)
0x00007ffff7ffaf45 <+245>: test %rsi,%rsi
0x00007ffff7ffaf48 <+248>: jne 0x7ffff7ffb0d5 <gettimeofday+645>
0x00007ffff7ffaf4e <+254>: xor %eax,%eax
0x00007ffff7ffaf50 <+256>: add $0x18,%rsp
0x00007ffff7ffaf54 <+260>: pop %rbx
0x00007ffff7ffaf55 <+261>: pop %r12
0x00007ffff7ffaf57 <+263>: pop %r13
0x00007ffff7ffaf59 <+265>: pop %r14
0x00007ffff7ffaf5b <+267>: pop %r15
0x00007ffff7ffaf5d <+269>: pop %rbp
0x00007ffff7ffaf5e <+270>: retq
; vread_pvclock ()
0x00007ffff7ffaf5f <+271>: mov -0x40(%rbp),%r13d
0x00007ffff7ffaf63 <+275>: cmp $0x1,%r13d
0x00007ffff7ffaf67 <+279>: mov %ebx,%ecx
0x00007ffff7ffaf69 <+281>: je 0x7ffff7ffb084 <gettimeofday+564>
0x00007ffff7ffaf6f <+287>: mov %ecx,%eax
0x00007ffff7ffaf71 <+289>: and $0xfff,%eax
0x00007ffff7ffaf76 <+294>: mov %eax,%edx
0x00007ffff7ffaf78 <+296>: mov %ecx,%eax
0x00007ffff7ffaf7a <+298>: mov %edx,-0x2c(%rbp)
0x00007ffff7ffaf7d <+301>: shr $0x6,%rdx
0x00007ffff7ffaf81 <+305>: and $0x3f,%eax
0x00007ffff7ffaf84 <+308>: add $0x200,%edx
0x00007ffff7ffaf8a <+314>: cmp $0x20f,%edx
0x00007ffff7ffaf90 <+320>: jg 0x7ffff7ffb107 <gettimeofday+695>
0x00007ffff7ffaf96 <+326>: shl $0xc,%edx
0x00007ffff7ffaf99 <+329>: mov %r12,%r10
0x00007ffff7ffaf9c <+332>: cltq
0x00007ffff7ffaf9e <+334>: movslq %edx,%rdx
0x00007ffff7ffafa1 <+337>: shl $0x6,%rax
0x00007ffff7ffafa5 <+341>: sub %rdx,%r10
0x00007ffff7ffafa8 <+344>: add %rax,%r10
0x00007ffff7ffafab <+347>: mov (%r10),%eax
0x00007ffff7ffafae <+350>: mov %eax,-0x30(%rbp)
0x00007ffff7ffafb1 <+353>: data32 xchg %ax,%ax
0x00007ffff7ffafb4 <+356>: lfence
0x00007ffff7ffafb7 <+359>: rdtsc
0x00007ffff7ffafb9 <+361>: shl $0x20,%rdx
0x00007ffff7ffafbd <+365>: mov %eax,%eax
0x00007ffff7ffafbf <+367>: movsbl 0x1c(%r10),%ecx
0x00007ffff7ffafc4 <+372>: or %rax,%rdx
0x00007ffff7ffafc7 <+375>: sub 0x8(%r10),%rdx
0x00007ffff7ffafcb <+379>: mov 0x18(%r10),%eax
0x00007ffff7ffafcf <+383>: mov %rdx,%r13
0x00007ffff7ffafd2 <+386>: shl %cl,%r13
0x00007ffff7ffafd5 <+389>: test %ecx,%ecx
0x00007ffff7ffafd7 <+391>: js 0x7ffff7ffb0bc <gettimeofday+620>
0x00007ffff7ffafdd <+397>: mov %eax,%edx
0x00007ffff7ffafdf <+399>: mov %r13,%rax
0x00007ffff7ffafe2 <+402>: mul %rdx
0x00007ffff7ffafe5 <+405>: shrd $0x20,%rdx,%rax
0x00007ffff7ffafea <+410>: mov %rax,%r13
0x00007ffff7ffafed <+413>: mov 0x10(%r10),%rax
0x00007ffff7ffaff1 <+417>: mov %rax,-0x38(%rbp)
0x00007ffff7ffaff5 <+421>: movzbl 0x1d(%r10),%eax
0x00007ffff7ffaffa <+426>: mov %al,-0x39(%rbp)
0x00007ffff7ffaffd <+429>: data32 xchg %ax,%ax
0x00007ffff7ffb000 <+432>: lfence
0x00007ffff7ffb003 <+435>: mov -0x2ff9(%rip),%eax # 0x7ffff7ff8010
0x00007ffff7ffb009 <+441>: mov %r11d,%ecx
0x00007ffff7ffb00c <+444>: cmp $0x1,%eax
0x00007ffff7ffb00f <+447>: mov %eax,-0x40(%rbp)
0x00007ffff7ffb012 <+450>: je 0x7ffff7ffb07f <gettimeofday+559>
0x00007ffff7ffb014 <+452>: and $0xfff,%ecx
0x00007ffff7ffb01a <+458>: cmp %ecx,-0x2c(%rbp)
0x00007ffff7ffb01d <+461>: jne 0x7ffff7ffaf5f <gettimeofday+271>
0x00007ffff7ffb023 <+467>: mov (%r10),%eax
0x00007ffff7ffb026 <+470>: test $0x1,%al
0x00007ffff7ffb028 <+472>: jne 0x7ffff7ffaf5f <gettimeofday+271>
0x00007ffff7ffb02e <+478>: cmp %eax,-0x30(%rbp)
0x00007ffff7ffb031 <+481>: jne 0x7ffff7ffaf5f <gettimeofday+271>
0x00007ffff7ffb037 <+487>: testb $0x1,-0x39(%rbp)
0x00007ffff7ffb03b <+491>: mov -0x38(%rbp),%rax
0x00007ffff7ffb03f <+495>: mov -0x2fbe(%rip),%rdx # 0x7ffff7ff8088
0x00007ffff7ffb046 <+502>: cmove %r15d,%r9d
0x00007ffff7ffb04a <+506>: add %r13,%rax
0x00007ffff7ffb04d <+509>: cmp %rdx,%rax
0x00007ffff7ffb050 <+512>: cmovb %rdx,%rax
0x00007ffff7ffb054 <+516>: sub %rdx,%rax
0x00007ffff7ffb057 <+519>: and -0x2fce(%rip),%rax # 0x7ffff7ff8090 ; gtod->mask
0x00007ffff7ffb05e <+526>: mov -0x2fcc(%rip),%edx # 0x7ffff7ff8098 ; gtod->mult
0x00007ffff7ffb064 <+532>: imul %rdx,%rax
; v = (cycles - gtod->cycle_last) & gtod->mask;
; return v * gtod->mult;
0x00007ffff7ffb068 <+536>: jmpq 0x7ffff7ffaed2 <gettimeofday+130>
0x00007ffff7ffb06d <+541>: nopl (%rax)
; mode = VCLOCK_PVCLOCK
0x00007ffff7ffb070 <+544>: mov -0x1f86(%rip),%eax # 0x7ffff7ff90f0 ; HPET_COUNTER
0x00007ffff7ffb076 <+550>: sub -0x2ff5(%rip),%rax # 0x7ffff7ff8088 ; gtod->cycle_last
0x00007ffff7ffb07d <+557>: jmp 0x7ffff7ffb057 <gettimeofday+519>
0x00007ffff7ffb07f <+559>: rdtscp
0x00007ffff7ffb082 <+562>: jmp 0x7ffff7ffb014 <gettimeofday+452>
0x00007ffff7ffb084 <+564>: rdtscp
0x00007ffff7ffb087 <+567>: jmpq 0x7ffff7ffaf6f <gettimeofday+287>
0x00007ffff7ffb08c <+572>: nopl 0x0(%rax)
0x00007ffff7ffb090 <+576>: data32 xchg %ax,%ax ; vread_tsc()
0x00007ffff7ffb093 <+579>: lfence ; rdtsc_barrier()
0x00007ffff7ffb096 <+582>: rdtsc ; __native_read_tsc()
0x00007ffff7ffb098 <+584>: shl $0x20,%rdx
0x00007ffff7ffb09c <+588>: mov %eax,%eax
0x00007ffff7ffb09e <+590>: or %rax,%rdx
0x00007ffff7ffb0a1 <+593>: mov -0x3020(%rip),%rax # 0x7ffff7ff8088 ; gtod->cycle_last
0x00007ffff7ffb0a8 <+600>: cmp %rax,%rdx
0x00007ffff7ffb0ab <+603>: jb 0x7ffff7ffb0c9 <gettimeofday+633>
0x00007ffff7ffb0ad <+605>: sub %rax,%rdx
0x00007ffff7ffb0b0 <+608>: mov %rdx,%rax
0x00007ffff7ffb0b3 <+611>: jmp 0x7ffff7ffb057 <gettimeofday+519>
0x00007ffff7ffb0b5 <+613>: xor %edx,%edx
0x00007ffff7ffb0b7 <+615>: jmpq 0x7ffff7ffaf13 <gettimeofday+195>
0x00007ffff7ffb0bc <+620>: neg %ecx
0x00007ffff7ffb0be <+622>: shr %cl,%rdx
0x00007ffff7ffb0c1 <+625>: mov %rdx,%r13
0x00007ffff7ffb0c4 <+628>: jmpq 0x7ffff7ffafdd <gettimeofday+397>
0x00007ffff7ffb0c9 <+633>: xor %eax,%eax
0x00007ffff7ffb0cb <+635>: jmp 0x7ffff7ffb057 <gettimeofday+519>
0x00007ffff7ffb0cd <+637>: mov %edx,%r8d ; r8d = gtod->seq
0x00007ffff7ffb0d0 <+640>: jmpq 0x7ffff7ffae86 <gettimeofday+54> ; retry
0x00007ffff7ffb0d5 <+645>: mov -0x2ffb(%rip),%eax # 0x7ffff7ff80e0
0x00007ffff7ffb0db <+651>: mov %eax,(%rsi)
0x00007ffff7ffb0dd <+653>: mov -0x2fff(%rip),%eax # 0x7ffff7ff80e4
0x00007ffff7ffb0e3 <+659>: mov %eax,0x4(%rsi)
0x00007ffff7ffb0e6 <+662>: xor %eax,%eax
0x00007ffff7ffb0e8 <+664>: jmpq 0x7ffff7ffaf50 <gettimeofday+256>
0x00007ffff7ffb0ed <+669>: pause
0x00007ffff7ffb0ef <+671>: mov -0x3076(%rip),%r8d # 0x7ffff7ff8080 ; gtod->seq
0x00007ffff7ffb0f6 <+678>: jmpq 0x7ffff7ffae86 <gettimeofday+54>
0x00007ffff7ffb0fb <+683>: mov $0x60,%eax // fallback
0x00007ffff7ffb100 <+688>: syscall
0x00007ffff7ffb102 <+690>: jmpq 0x7ffff7ffaf50 <gettimeofday+256>
0x00007ffff7ffb107 <+695>: ud2
End of assembler dump.The vDSO is mapped to a new address each time (probably, some security feature). However, the function is always placed at the same address as above (0x00007ffff7ffae50)
when run under gdb (I’m not sure what causes this). The function accesses some memory at addresses not far from its code (such as 0x7ffff7ff8080 or 0x7ffff7ff90f0), always using
the “relative-to-IP” addressing mode. This makes this function completely relocatable – it can be mapped to any address in the user space, together with all its
data.
We can see that the function employs various options. It can make a syscall, it can execute an rdtsc instruction, or it can just read some memory (in a similar
fashion to the Windows implementation). Which of these options is applied in our case?
Let’s look at the source code of our version of Linux kernel (3.17.4). Note that this is not the latest one (Linux distributors are very conservative people). The code
of the latest one differs quite a bit (including some constant definitions). Here is the code (in arch/x86/vdso/vclock_gettime.c):
notrace int __vdso_gettimeofday(struct timeval *tv, struct timezone *tz)
{
if (likely(tv != NULL)) {
if (unlikely(do_realtime((struct timespec *)tv) == VCLOCK_NONE))
return vdso_fallback_gtod(tv, tz);
tv->tv_usec /= 1000;
}
if (unlikely(tz != NULL)) {
tz->tz_minuteswest = gtod->tz_minuteswest;
tz->tz_dsttime = gtod->tz_dsttime;
}
return 0;
}Here is the rest of the code (gtod, obviously, stands for gettimeofday). In
arch/x86/include/asm/vgtod.h:
struct vsyscall_gtod_data {
unsigned seq;
int vclock_mode;
cycle_t cycle_last;
cycle_t mask;
u32 mult;
u32 shift;
/* open coded 'struct timespec' */
u64 wall_time_snsec;
gtod_long_t wall_time_sec;
gtod_long_t monotonic_time_sec;
u64 monotonic_time_snsec;
gtod_long_t wall_time_coarse_sec;
gtod_long_t wall_time_coarse_nsec;
gtod_long_t monotonic_time_coarse_sec;
gtod_long_t monotonic_time_coarse_nsec;
int tz_minuteswest;
int tz_dsttime;
};
static inline unsigned gtod_read_begin(const struct vsyscall_gtod_data *s)
{
unsigned ret;
repeat:
ret = ACCESS_ONCE(s->seq);
if (unlikely(ret & 1)) {
cpu_relax();
goto repeat;
}
smp_rmb();
return ret;
}
static inline int gtod_read_retry(const struct vsyscall_gtod_data *s,
unsigned start)
{
smp_rmb();
return unlikely(s->seq != start);
}In arch/x86/include/asm/vvar.h:
#define VVAR(name) (vvar_ ## name)Back in arch/x86/vdso/vclock_gettime.c):
#define gtod (&VVAR(vsyscall_gtod_data))
notrace static int __always_inline do_realtime(struct timespec *ts)
{
unsigned long seq;
u64 ns;
int mode;
do {
seq = gtod_read_begin(gtod);
mode = gtod->vclock_mode;
ts->tv_sec = gtod->wall_time_sec;
ns = gtod->wall_time_snsec;
ns += vgetsns(&mode);
ns >>= gtod->shift;
} while (unlikely(gtod_read_retry(gtod, seq)));
ts->tv_sec += __iter_div_u64_rem(ns, NSEC_PER_SEC, &ns);
ts->tv_nsec = ns;
return mode;
}What is going on here is very close to what happened in Windows. There is a data structure that accompanies the vDSO and is mapped to the address space of every
process. It is called vvar_vsyscall_gtod_data and is addressed in the code via the pseudo-variable gtod. In the assembly listing above this structure sits at
the address 0x7ffff7ff8080.
Some background thread updates the fields of this structure at regular intervals. Since there are more than two of these fields, the Windows trick of writing the
high part of the number twice doesn’t work. However, a similar trick works. The writer maintains a version number of the data in the structure (the seq field).
It gets incremented by one when the writer starts updating the structure, and again by one after it finishes (with appropriate write barrier instruction being used).
As a result, the odd value means that the data isn’t consistent. The reader must read the number, make sure it’s even (wait a bit using pause instruction if not), read all the values of
interest from the structure, read the version number again, and if it is the same as in the beginning, the data is considered correct. This is what gtod_read_begin
and gtod_read_retry functions are for.
Read barrier instructions must be used to make sure that the processor didn’t re-order reading the version number with reading of the actual data. However,
the strong memory ordering of Intel x86 makes this unnecessary, so the read barrier call (smp_rnb()) is empty in our case.
The values of interest are wall_time_sec and wall_time_snsec. The first one is the proper number of seconds since the epoch as reported by the good old
time() call. In fact, time() is implemented by reading exactly this value, and without any locking or version control:
notrace time_t __vdso_time(time_t *t)
{
/* This is atomic on x86 so we don't need any locks. */
time_t result = ACCESS_ONCE(gtod->wall_time_sec);
if (t)
*t = result;
return result;
}The second value is the nanoseconds time, relative to the last second, shifted left by gtod->shift, Or, rather, it the time measured in some
units, which becomes the nanosecond time when shifted right by gtod->shift, which, in our case, is 25. This is very high precision.
One nanosecond divided by 225 is about 30 attoseconds. Perhaps, Linux kernel designers looked far ahead, anticipating the future when we’ll need such
accuracy for our time measurement.
What is the real resolution of these time values? Let’s read these values in a loop and print them when they change.
Unless we want to run the program in gdb, we must first resolve the vDSO relocation. That’s easy:
const struct vsyscall_gtod_data * gtod = 0;
void resolve (void)
{
unsigned char * p;
struct timeval time;
gettimeofday (&time, 0);
p = (char *) gettimeofday;
if (p[0] != 0xFF || p[1] != 0x25) {
exit (1);
}
p += 6 + *(int32_t*) (p+2);
p = * (unsigned char **) p;
p -= (unsigned) (intptr_t) p & 0xFFF;
p -= 0x2000;
p += 0x80;
gtod = (const struct vsyscall_gtod_data *) p;
}Now we can run a loop to detect change in wall_time_snsec:
void test (void)
{
int i;
uint64_t oldns = 0;
for (i = 0; i < 10000000; i++) {
uint64_t ns = gtod->wall_time_snsec;
if (ns != oldns) {
printf ("%d: sec=%lu ns=%lu diff=%ld ns_shift=%lu diff_shift=%ld\n",
i, gtod->wall_time_sec, ns, ns - oldns, ns >> gtod->shift,
(ns >> gtod->shift) - (oldns >> gtod->shift));
}
oldns = ns;
}
}A typical fragment of the output:
3721507: sec=1499630953 ns=16894552383987602 diff=33554102663246 ns_shift=503496896 diff_shift=999990
4367859: sec=1499630953 ns=16928106486650848 diff=33554102663246 ns_shift=504496886 diff_shift=999990
5014216: sec=1499630953 ns=16961660589326449 diff=33554102675601 ns_shift=505496877 diff_shift=999991
We see that the wall_time_nsec value is updated rather infrequently: for about 650000 iterations it stays the same and then jumps by a big value, which,
being shifted by shift, becomes 999990 ns, or almost exactly one millisecond. It’s also interesting to see what happens when wall_time_sec changes:
249316536: sec=1499631433 ns=33542778622228903 diff=33554096688437 ns_shift=999652702 diff_shift=999990
250511726: sec=1499631434 ns=21900718852443 diff=-33520877903376460 ns_shift=652692 diff_shift=-999000010
The new nanosecond value doesn’t start at zero; it starts at 652692, which is over half a millisecond. It’s not always that big – I saw values of 200K and 300K.
In short, two variables available in the gtod structure provide very fast access to a rather coarse time value with a one millisecond resolution. Just like in Windows.
However, gettimeofday() does not stop here. It tries to improve accuracy using other methods. In the code above this is what the vgetsns() function is responsible
for:
notrace static inline u64 vgetsns(int *mode)
{
u64 v;
cycles_t cycles;
if (gtod->vclock_mode == VCLOCK_TSC)
cycles = vread_tsc();
#ifdef CONFIG_HPET_TIMER
else if (gtod->vclock_mode == VCLOCK_HPET)
cycles = vread_hpet();
#endif
#ifdef CONFIG_PARAVIRT_CLOCK
else if (gtod->vclock_mode == VCLOCK_PVCLOCK)
cycles = vread_pvclock(mode);
#endif
else
return 0;
v = (cycles - gtod->cycle_last) & gtod->mask;
return v * gtod->mult;
}The idea is that somewhere in the system there is a high-frequency timer, which we can ask for a current tick count. We record the reading of that timer at the
last tick of the coarse timer (gtod->cycle_last), and get the difference. The gtod->mask and gtod->mult fields help convert the reading of that timer to our
30-attosecond units. This can explain the choice of those units: it’s not that Linux designers wanted to measure times of molecular processes; the unit is chosen very small
to reduce the errors during this conversion.
The code above provides for three types of high-frequency timers: TSC (based on the RDTSC instruction of Intel x86 instruction set), HPET (based on the external
hardware, the HPET chip), and PVCLOCK, which, most probably, has something to do with running in the VM environment.
In any case, the code only makes use of the high-precision timer to get the offset from the coarse time. The timer doesn’t have to run very stable for years. It is
only supposed to be stable enough to provide the time offset between the coarse timer ticks. Moreover, its clock frequency may vary, as long as that variance is
known to the system and reflected in appropriate update of the mask and mult fields. The system is very well designed to provide very accurate time very fast.
So what went wrong?
In our case, the vclock_mode field is set to 2, which means using the HPET (High Precision Event Timer). This timer is a hardware piece included into all modern PCs: a replacement of
the good old 8253/8254 chip. That chip ran a counter, which, upon reaching zero, could trigger an interrupt, and could also be read directly using IN instructions. It ran at the
frequency of 1.19318 MHz, and, if programmed to expire every 65536 clocks, caused an interrupt every 55 ms (18.2 Hz), which we all remember since the MS DOS days.
The HPET runs at higher frequency, counts up rather than down, and is available via memory-mapped I/O rather than I/O ports. The routine to read the counter looks like this:
static notrace cycle_t vread_hpet(void)
{
return *(const volatile u32 *)(&hpet_page + HPET_COUNTER);
}This is compiled into just one 32-bit memory read instruction:
0x00007ffff7ffb070 <+544>: mov -0x1f86(%rip),%eax # 0x7ffff7ff90f0The entire gettimeofday in the case of a HPET time source is compiled into a sequence of memory reads plus some shifts and multiplications. No divisions or
other expensive operations are present. Why is it then executing so slowly?
I didn’t have a sampling profiler available on the test machine, but there is a poor man’s solution: to attach gdb to a running program that executes gettimeofday in a loop, and then interrupt it.
In all the cases that I tried it it always stopped at exactly one place: after the above-mentioned instruction (at gettimeofdat+550). This indicates that that instructions
alone takes most of the execution time. This is easy to verify. Let’s resolve the hpet_page in a similar way to resolving vsyscall_gtod_data and read this variable
in a loop:
Time for 1000000: 0.564707 s; ns/iter=564.707000
It takes more than half a microsecond to read the data from a HPET timer, which makes it a very slow time source. If we print the values we read from this timer,
we’ll see that, unlike in the case of gtod->wall_time_snsec, the values change each time we access the timer. The typical difference is 8, which means that the timer
ticks 8 times while being read. The timer’s accuracy is way higher than its performance. The difference between timer values measured at the points when the
coarse nanoseconds change (which, as we learned, happens every millisecond), is 14320, which means that the HPET frequency is 14.32 MHz (70 ns per tick)..
This is really sad: the timer runs at high frequency, but there is no way to read it at this frequency. We can read it at about 1.8 MHz, which is just a bit higher than the frequency of the MS DOS timer.
And the worst part is that in our use case we are in fact uninterested in such a high accuracy anyway – all we need is currentTimeMillis(), and the coarse
timer is perfectly suitable for that.
The coarse timer
There is an easy way out, because the coarse timer is available via the user API: the clock_gettime() function:
int clock_gettime(clockid_t clk_id, struct timespec *tp);Among multiple values defined in <time.h> for clk_id there is one that does exactly what we need: CLOCK_REALTIME_COARSE (value 5).
The code for this function is present in the same vDSO (vclock_gettime.c):
notrace static void do_realtime_coarse(struct timespec *ts)
{
unsigned long seq;
do {
seq = gtod_read_begin(gtod);
ts->tv_sec = gtod->wall_time_coarse_sec;
ts->tv_nsec = gtod->wall_time_coarse_nsec;
} while (unlikely(gtod_read_retry(gtod, seq)));
}The nanosecond times reported by this function are 999991 ns (1 ms) apart, and the execution takes 8.4 ns.
The TSC time source
We’ve learned that the slow execution of currentTimeMillis() was caused by two factors:
- JVM using
gettimeofday()instead ofclock_gettime() gettimeofday()being very slow if HPET time source is used.
HPET, however, isn’t the only time source these days. Perhaps, not even the most common: many systems use TSC. This could make the entire study irrelevant. However, in our project the servers are configured with the HPET time source for a reason: this time source integrated well with the NTP client, allowing for smooth time adjustment, while TSC was not as stable (I don’t know the details; this is what the local Linux gurus say and I have no option but to trust them). Some other developers may find themselves in the same situation. Besides, a Java developer can’t always know what time source will be configured on the machine the program will run. That’s why I feel that the findings made so far are still important.
However, it is still interesting to find out how the result would change if we used the TSC time source. TSC stands for the time stamp counter,
which is simply the number of CPU cycles counted since the startup time (it is only 64-bit wide, so it will wrap around in 243 years at 2.4GHz clock rate).
This value can be read using rdtsc instruction. Traditionally, there were two problems with this value:
- the values from different cores or physical processors may be shifted against each other, as the processors may start at different times
- the clock frequency of a processor may change during execution.
The first one seems to be indeed a problem. I tried getting the rdtsc value from several cores at once, synchronised on writing into some memory location.
Even in the best case I got differences of a couple of thousand cycles. Sometimes more. However, this is only a problem if the programmer wants to use the TSC
manually; in this case the thread affinity must be set accordingly. The OS knows when it re-schedules threads from one core to another, so it can make all necessary adjustments.
The second problem seems to be a thing of the past. The Intel doc says this:
Processor families increment the time-stamp counter differently:
For Pentium M processors (family [06H], models [09H, 0DH]); for Pentium 4 processors, Intel Xeon processors (family [0FH], models [00H, 01H, or 02H]); and for P6 family processors: the time-stamp counter increments with every internal processor clock cycle. The internal processor clock cycle is determined by the current core-clock to busclock ratio. Intel® SpeedStep® technology transitions may also impact the processor clock.
For Pentium 4 processors, Intel Xeon processors (family [0FH], models [03H and higher]); for Intel Core Solo and Intel Core Duo processors (family [06H], model [0EH]); for the Intel Xeon processor 5100 series and Intel Core 2 Duo processors (family [06H], model [0FH]); for Intel Core 2 and Intel Xeon processors (family [06H], DisplayModel [17H]); for Intel Atom processors (family [06H], DisplayModel [1CH]): the time-stamp counter increments at a constant rate.
It also says:
Processor’s support for invariant TSC is indicated by CPUID.80000007H:EDX[8].
This we can test:
uint32_t __attribute__ ((noinline)) cpuid (void)
{
asm (
"mov $0x80000007, %eax\n"
"cpuid\n"
"mov %edx, %eax\n"
);
}
void test (void)
{
printf ("%X\n", cpuid ());
}prints
100
which indicates that the bit is set.
Additional testing confirms this:
void __attribute__ ((noinline)) rdtsc (uint64_t * p)
{
asm (
"lfence\n"
"rdtsc\n"
"mov %eax,(%rdi)\n"
"mov %edx, 4(%rdi)\n"
);
}
uint64_t micros (void)
{
struct timeval time;
gettimeofday (&time, 0);
return time.tv_sec * 1000000 + time.tv_usec;
}
void delay (void)
{
int i;
double s = 0;
for (i = 1; i < 1000000000; i++) s += 1.0 / i;
printf ("%f\n", s);
}
void test (void)
{
uint64_t t0, t1;
uint64_t c0, c1;
t0 = micros ();
rdtsc (&c0);
sleep (10);
// delay ();
t1 = micros ();
rdtsc (&c1);
printf ("time: %d; clocks/nano: %f\n", (t1 - t0), (c1 - c0) / 1000.0 / (t1 - t0));
}Let’s enable turbo boost and run it at known processor:
# taskset 1 ./t
time: 10000102; clocls/nano: 2.399990
While it is running, we’ll check the clock speed of processor zero:
# cat /proc/cpuinfo | grep MHz |head -n 1
cpu MHz : 1337.156
Now we comment out sleep, uncomment delay and repeat:
# taskset 1 ./t
time: 8478796; clocls/nano: 2.399991
And the clock speed is
# cat /proc/cpuinfo | grep MHz |head -n 1
cpu MHz : 3199.968
The rate of the rdtsc is the same and it equals to the nominal clock rate of the processor, which in both cases differed from the real clock rate
of the corresponding core.
This means that TSC is quite safe to use on these processors. One way to do this is by using the function clock_gettime mentioned above. It has a clock id
that corresponds to TSC: CLOCK_PROCESS_CPUTIME_ID.
The speed, however, isn’t great: we get 343 ns per call.
There is a better option: we keep using the gettimeofday but set the TSC as a preferable time source for the entire system. This is very easy:
echo tsc > /sys/devices/system/clocksource/clocksource0/current_clocksource
To return it back to HPET we do the same, but use “hpet” instead of “tsc”.
This is temporary (does not survive reboot). Let’s go straight back to our Java program and put two zeroes back into the repetition count. The result is amazing:
# java Time
Sum = 2414988828092895332; time = 3636; or 36.36 ns / iter
Sum = 2414989192017338494; time = 3628; or 36.28 ns / iter
Sum = 2414989551179770420; time = 3604; or 36.04 ns / iter
This isn’t as good as in Windows (there it was under 4 ns), but still much better than before, and, probably, practically usable for the use cases listed in the beginning.
If we time gettimeofday(), we get:
time for 100000000: 3.000262 s; ns/iter=30.002621
Since gettimeofday() returns time in microseconds, the natural limit of its resolution is 1000 ns, and it is indeed achieved. If we call this function many times
and print the differences between consecutive values, we get many zeroes and occasional ones.
The same test for clock_gettime (CLOCK_REALTIME) returns 30 ns – exactly the same as the execution time of each call, which is expected.
In short, the TSC time source is both very fast and very accurate, with two reservations:
- on some systems there may be reasons not to use it
- the
clock_gettime(CLOCK_REALTIME_COARSE)is faster.
Multi-threaded performance
The currentTimeMillis() based on HPET runs for 640 ns (1.5M operations/second). Is this per core or for the entire system?
Let’s run a similar test to Time.java, but start N threads, where N is between 1 and 24 (the total number of cores in our dual-processor system,
including hyper-threading ones).
Here are the results for the small numbers of threads:
| Thread count | Avg time/call, ns | Total calls/sec, mil |
|---|---|---|
| 1 | 644 | 1.55 |
| 2 | 918 | 2.18 |
| 3 | 1366 | 2.20 |
| 4 | 1871 | 2.14 |
Here is the average time it takes to execute currentTimeMillis() for all thread counts:
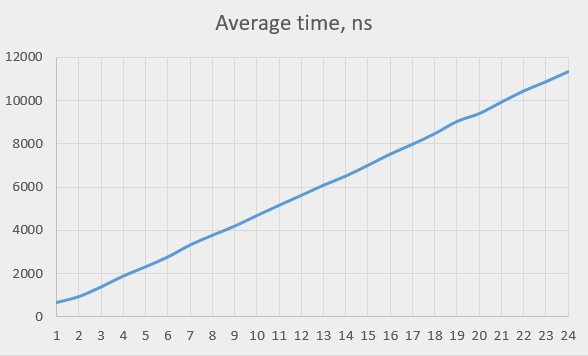
This looks quite linear, which makes us suspect that the HPET chip serialises the requests, only serving one at a time. Or, possibly, a little bit more than one, judging from the transition from thread count 1 to thread count 2, where the performance didn’t halve, but rather dropped by 1.5 times.
Here is the graph of the total performance of the system (the number of calls that can be performed on all cores and processors, in one second):
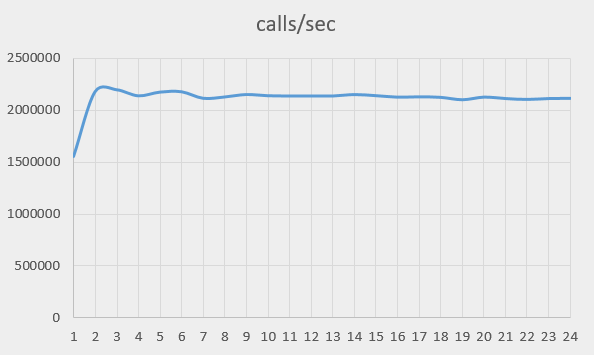
The performance went up from 1.5M to about 2.1M op/sec and stayed there. The initial increase may have something to do with the fact that we’re testing on a dual-processor
system. Here are the times measured when the execution is limited to one processor (taskset 0x555):
| Thread count | Avg time/call, ns, two processors | Avg time/call, ns, one processor |
|---|---|---|
| 1 | 644 | 596 |
| 2 | 918 | 1105 |
| 3 | 1366 | 1672 |
| 4 | 1871 | 2245 |
The single-processor time does not show that abnormal step between one and two threads; it is roughly proportional to the number of threads and (except for the value for one thread) is longer than the dual-processor time.
Testing with multiple processes gives similar results to that with multiple threads.
In short, the performance of the HPET is indeed limited system-wide. Not more than two million time enquiries per second can be performed on the machine, no
matter how we split the load between cores and processes. If 24 cores are loaded evenly, each can perform below 100K operations per second. This means that one must
really be careful when using currentTimeMillis() in Java programs (and gettimeofday() in C) if there are chances that the program will be executed using
HPET. This also applies to the use of C++ time-reporting functionality (such as std::chrono::system_clock::now ()), for it uses clock_gettime (CLOCK_REALTIME),
which ends up reading the same HPET registers (although it invokes a syscall in the process).
[A side note. Since the processors affect each other when using HPET, there are potential security problems. One process may run a tight loop calling gettimeofday,
thus starving all the other processes of access to this resource and reducing their performance. Alternatively, some process may call this function and time its execution
using TSC, detect this way when other processes query current time, which may help establish which execution path the other processes take. End of side note]
The TSC-based timer does not demonstrate this behaviour. Its performance is quite stable, only dropping by 40% when all the cores (including the hyper-threading ones) are used:
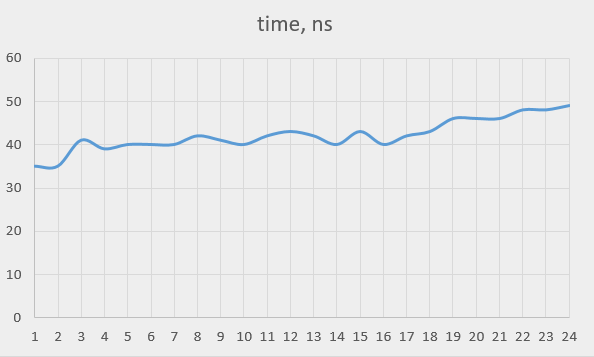
Off-topic: A system call
We’ve seen that the vDSO code can end up in the system call. In Intel x64 version of Linux, the system call 0x60 is exactly the gettimeofday function.
How fast is this system call? We can call it directly, modifying the original time measurement of gettimeofday. We just replace
gettimeofday (&time, 0);with
syscall (0x60, &time, 0);This is what we get:
| Time source | Time for vDSO, ns | Time for syscall, ns | Cost of syscall, ns |
|---|---|---|---|
| HPET | 644 | 734 | 90 |
| TSC | 35 | 91 | 56 |
Previously, I believed that system calls in Linux were incredibly expensive. This measurement proves this belief false: a system call isn’t exactly free, but it is cheaper, for example, than an L3 cache miss (100 ns).
However, if the performed action is short (as it is for TSC gettimeofday), it is still beneficial to avoid system call. The vDSO really helps here: in our case,
it made the execution almost three times faster.
What to do
The first prize is to make sure that the program only ever runs on Windows or on Linux with the TSC time source. If this is impossible, there is no way to speed
the call up while staying in pure Java, and then the solution is to make sure currentTimeMillis() isn’t called too often. Obviously, one can implement
a custom version of this call using JNI, based on clock_gettime() or even direct reading of TSC (in the latter case thread affinity control may be required).
We measured the cost of a JNI call here; it was 8 ns. The total cost will be under 20 ns, which is acceptable.
Conclusions
-
The title isn’t completely correct:
currentTimeMillis()isn’t always slow. However, there is a case when it is. -
This call is lightning fast on Windows (4 ns), and reasonably fast on Linux with TSC time source (36 ns)
-
It is indeed slow on Linux with HPET time source: 640 ns.
-
The HPET is shared between all running threads, of all processes so the entire system can query it only two million times per second.
-
Even this “slow” timer is sufficient for most applications. However, there are cases where higher performance is required.
-
There is an API call that returns coarse time and works fast. This is the
clock_gettime(). Java VM could have used this call and provide fastcurrentTimeMillis(). If absolutely necessary, one can implement it her/himself using JNI. -
A Linux system call isn’t as dramatically slow as I believed, but still takes substantial time (50 – 100 ns).
Update: nanoTime
During the discussion on reddit I received multiple comments pointing out that
System.currentTimeMillis() is in fact a bad choise of call for the first three of the use cases listed in the beginning. The System.nanoTime() is the correct
one. The reason is that nanoTime() is monotonic while currentTimeMillis() is not. The latter may be affected by time adjustments from NTP daemon or by leap seconds.
Or, for that matter, by user-initiated time change.
Even though these factors do not apply to our project (the machines are synchronised with the GPS time when booted, and later adjusted by sub-millisecond intervals; as a result, time never jumps back during program run: it only can stall for a bit), I fully agree with this comment. I would gladly have used a monotonic coarse timer if there was one in Java.
It is a bit awkward that Java provides two functions that differ by two parameters – the nature of time and the resolution. These parameters are orthogonal and grant the need for four functions:
- monotonic coarse
- monotonic fine (
nanoTime) - real-time coarse (
currentTimeMillis) - real-time fine.
Two are provided. There is, however, need for the remaining two. The last one, for instance, may be useful to timestamp events in high-frequency trading.
And what we needed was actually the first one. In fact, the only reason we needed coarse timer in the first place was that it had a potential to be fast. Actually, this is the only reason for coarse timers to exist at all.
If coarse timers are not much faster than fine ones, they are not needed. Two types of timers are sufficient then. This, unfortunately, seems to be the
case: coarse timers are not faster, due to currentTimeMillis being implemented using gettimeofday().
Here are the evaluation times of nanoTIme() compared to currentTimeMillis():
| Java method | Windows, ns | Linux, HPET, ns | Linux, TSC, ns |
|---|---|---|---|
| currentTimeMillis() | 4 | 640 | 36 |
| nanoTime() | 16 | 639 | 35 |
The nanosecond timer is a bit slower than the millisecond one on Windows, but it is still fast enough. The Linux version runs at the same speed as the milli timer. This is how the Linux version is implemented:
jlong os::javaTimeNanos() {
if (Linux::supports_monotonic_clock()) {
struct timespec tp;
int status = Linux::clock_gettime(CLOCK_MONOTONIC, &tp);
assert(status == 0, "gettime error");
jlong result = jlong(tp.tv_sec) * (1000 * 1000 * 1000) + jlong(tp.tv_nsec);
return result;
} else {
timeval time;
int status = gettimeofday(&time, NULL);
assert(status != -1, "linux error");
jlong usecs = jlong(time.tv_sec) * (1000 * 1000) + jlong(time.tv_usec);
return 1000 * usecs;
}
}It calls clock_gettime function with CLOCK_MONOTONIC parameter, which ends up in the same vDSO, in the function do_monotonic:
notrace static int __always_inline do_monotonic(struct timespec *ts)
{
unsigned long seq;
u64 ns;
int mode;
do {
seq = gtod_read_begin(gtod);
mode = gtod->vclock_mode;
ts->tv_sec = gtod->monotonic_time_sec;
ns = gtod->monotonic_time_snsec;
ns += vgetsns(&mode);
ns >>= gtod->shift;
} while (unlikely(gtod_read_retry(gtod, seq)));
ts->tv_sec += __iter_div_u64_rem(ns, NSEC_PER_SEC, &ns);
ts->tv_nsec = ns;
return mode;
}The timer type is controlled by the same vclock_mode parameter as for do_realtime, which is used in gettimeofday. The execution ends up in the same vgetsns(),
which either reads HPET registers or performs rdtsc. The only difference is in the coarse values it reads: gtod->monotonic_time_* instead of gtod->wall_time_*.
No wonder it runs at the same speed.
The fact that both real-time and monotonic clocks share the same mode is unfortunate. As I said earlier, the reason for us to use HPET
was that it co-operated with the NTP daemon better. Since monotonic time isn’t affected by NTP, it could have been based on TSC.
When TSC is used, consecutive calls to nanoTime() return values that are about 80 ns apart. Consecutive calls to clock_gettime() return intervals of about 48 – 50 ns.
It looks like the accuracy of nanoTime() is only limited by its own duration (36 ns; the remaining 12 ns must be the test overhead).
The Windows version looks like this:
jlong os::javaTimeNanos() {
if (!has_performance_count) {
return javaTimeMillis() * NANOSECS_PER_MILLISEC; // the best we can do.
} else {
LARGE_INTEGER current_count;
QueryPerformanceCounter(¤t_count);
double current = as_long(current_count);
double freq = performance_frequency;
jlong time = (jlong)((current/freq) * NANOSECS_PER_SEC);
return time;
}
}Here performance_frequency comes from the call to QueryPerformanceFrequency, which, on my PC, returns 2648441. This is the timer frequency in Hz, and it is
rather low. Windows can measure time very fast (in 16 ns), but in rather big increments (one tick equals 377.5 ns). Test in Java confirms it: continuous
calls to nanoTime() return results that differ by zeroes and occasional 377s.
Out of curiosity, let’s look at the code of QueryPerformanceCounter (this time in 64-bit mode only):
00007FFE4C272230 push rbx
00007FFE4C272232 sub rsp,20h
00007FFE4C272236 mov al,byte ptr [7FFE03C6h]
00007FFE4C27223D mov rbx,rcx
00007FFE4C272240 cmp al,1
00007FFE4C272242 jne 00007FFE4C272274
00007FFE4C272244 mov rcx,qword ptr [7FFE03B8h]
00007FFE4C27224C rdtsc
00007FFE4C27224E shl rdx,20h
00007FFE4C272252 or rax,rdx
00007FFE4C272255 mov qword ptr [rbx],rax
00007FFE4C272258 lea rdx,[rax+rcx]
00007FFE4C27225C mov cl,byte ptr [7FFE03C7h]
00007FFE4C272263 shr rdx,cl
00007FFE4C272266 mov qword ptr [rbx],rdx
00007FFE4C272269 mov eax,1
00007FFE4C27226E add rsp,20h
00007FFE4C272272 pop rbx
00007FFE4C272273 ret I didn’t include the code where jne goes if al (as loaded from 7FFE03C6h) is not equal to 1, because in my case it is. Probably, this is the flag that tells
it to use rdtsc. The value is read, added to the number from 7FFE03B8h (probably, some base value), and then shifted right by the number in 7FFE03C7h.
This number is 10 in our case. This explains the magical value of 2648441 for the performance frequency: it is the clock frequency of the TSC on this computer
(2.7 GHz) divided by 1024. The resolution could have been higher if smaller shift factor was chosen.
Conclusions of the Update
-
Coarse timers in Java are not much faster than the fine timers. This means that fine timers could be used everywhere if fine real-time one was provided
-
on Linux, the
nanoTimeperformance in TSC mode is mostly satisfactory; in HPET mode it is not. -
on Windows the
nanoTimeis four times slower thancurrentTimeMillisbut still fast enough; the resolution, however, is far from ideal, for unknown reason.
Comments are welcome below or on reddit.